2025年振り返り
2025年の振り返りとしてやったことをまとめる。
論文
LayerX Bet AI Dayで積んでる論文をサクサク消化する技術という発表をした。発表時代が夏だったこともあり、やり方にも変化があった。具体的にはDifyでの要約はほぼ読まなくなり、NotebookLMでpodcastを生成し、移動中にスクリーニング。スクリーニングして高評価(概ね4以上)は要約ではなく、全文読むようになった。
Notion上で読んだ論文のステータス管理と内容メモを残しているが、190本が「済」となった。
前年比+179本 from 11本。ただし昨年は11月頃から開始のため、通年での記録は今年が初。
podcastによるスクリーニング時に5段階で精読するか(4以上は精読する)を判断しているが、スコアの分布は以下のようになった。今年の後半はエージェントメモリの論文を手当たり次第NotebookLMに放り込んでいたが、品質よりもスピード重視でarxivに公開されることも多く、8割程度が評価「2」以下であった。こういった論文を効率的にスクリーニングできている点は良い。

評価「4」とした論文
- MIRAGE: Scaling Test-Time Inference with Parallel Graph-Retrieval-Augmented Reasoning Chains
- Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion
- Towards Teachable Reasoning Systems: Using a Dynamic Memory of User Feedback for Continual System Improvement
- Keep Me Updated! Memory Management in Long-term Conversations
- Resolving Knowledge Conflicts in Large Language Models
- Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
- Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
- Devil's Advocate: Anticipatory Reflection for LLM Agents
評価「5」とした論文
- Solving a Million-Step LLM Task with Zero Errors)
- Dremel: Interactive Analysis of Web-Scale Datasets
- Zep: A Temporal Knowledge Graph Architecture for Agent Memory)
エージェントメモリに興味があったのが浮き彫りになっている。同時にBigQueryの原論文とも呼ぶべきDremelを読んだ。新しい論文ばかりではなく、歴史上も重要な論文を少しずつ精読していこうと思う。
書籍
- 書籍:
28冊(前年比+13冊 from 15冊) - 漫画:
88冊(前年記録なし) - ライトノベル:
6冊(前年記録なし)
特に読んで良かった本
- ソフトウェアアーキテクチャ・ハードパーツ ―分散アーキテクチャのためのトレードオフ分析
- トヨタ物語 (強さとは「自分で考え、動く現場」を育てることだ)
- 2030 半導体の地政学(増補版) 戦略物資を支配するのは誰か
技術書
- Clean Architecture 達人に学ぶソフトウェアの構造と設計(Robert C.Martin/KADOKAWA)
- 深層ニューラルネットワークの高速化 (ML Systems)(佐藤 竜馬/技術評論社)
- 改訂新版 良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方(仙塲 大也/技術評論社)
- 生成AIのしくみ 〈流れ〉が画像・音声・動画をつくる(岡野原 大輔/岩波書店)
- ソフトウェアアーキテクチャ・ハードパーツ ―分散アーキテクチャのためのトレードオフ分析(Neal Ford,Mark Richards,Pramod Sadalage,Zhamak Dehghani/オライリー・ジャパン)
- Effective Python 第2版 ―Pythonプログラムを改良する90項目(Brett Slatkin/オライリー・ジャパン)
- ロバストPython ―クリーンで保守しやすいコードを書く(Patrick Viafore/オライリー・ジャパン)
- LLMのプロンプトエンジニアリング ―GitHub Copilotを生んだ開発者が教える生成AIアプリケーション開発(John Berryman,Albert Ziegler,服部 佑樹,佐藤 直生/オライリー・ジャパン)
- チームトポロジー 価値あるソフトウェアをすばやく届ける適応型組織設計(マシュー・スケルトン,マニュエル・パイス/日本能率協会マネジメントセンター)
- 達人に学ぶDB設計徹底指南書 第2版(ミック/翔泳社)
ビジネス書
- トヨタ物語 (強さとは「自分で考え、動く現場」を育てることだ)(野地秩嘉/日経BP)
- 2030 半導体の地政学(増補版) 戦略物資を支配するのは誰か(太田泰彦/日経BP)
- ユニクロ(杉本 貴司/日経BP)
- WHITE SPACE ホワイトスペース: 仕事も人生もうまくいく空白時間術(ジュリエット・ファント/東洋経済新報社)
- エッセンシャル思考 最少の時間で成果を最大にする(グレッグ・マキューン/かんき出版)
- サイゼリヤ元社長が教える 年間客数2億人の経営術(堀埜 一成/ディスカヴァー・トゥエンティワン)
- リーダーシップの本質: 真のリーダーシップとは何か(堀 紘一/ダイヤモンド社)
- 都市計画の世界史(日端 康雄/講談社)
- AI覇権 4つの戦場(ポール・シャーレ/早川書房)
- 世界はシステムで動く ―― いま起きていることの本質をつかむ考え方(ドネラ・H・メドウズ,Donella H. Meadows/英治出版)
- これからの「正義」の話をしよう(マイケル・サンデル,Michael J. Sandel/早川書房)
- 魚の教養見るだけノート(宝島社)
- 影響力の武器[新版]:人を動かす七つの原理(ロバート・B・チャルディーニ/誠信書房)
- 新版 思考の整理学(外山 滋比古/筑摩書房)
- お金の流れでわかる世界の歴史 富、経済、権力・・・・・・はこう「動いた」(大村 大次郎/KADOKAWA)
- 戦略読書 〔増補版〕(三谷 宏治/日本経済新聞出版)
- タリバン(田中 宇/光文社)
小説
- 三体観想之宙(宝樹/早川書房)
記事
記事そのものではないが、7月にPocketがサービス終了してしまったのが困った。記事の読み上げ機能はないが、以下の点でInstapaperに移行した。
- PCブラウザからショートカットでsaveできる
- iOSアプリがある
- iOSアプリ上で、お気に入りができる(以下の読んでよかった記事を整理するため)
- iOSアプリ上からブラウザを開いたり、アーカイブの動作が自分の好みに合っている
以下は今年読んでよかった記事。 こうして眺めてみるとAnthoropicのテックブログは打率が高い。ここではSkillsの記事を載せなかったが、claude codeを泥臭く開発する過程で得られた知見を惜しげもなくブログとして公開し、LLM、とりわけエージェントの技術トレンドを生み出すパワーが凄まじい。
Python
- zhanymkanov/fastapi-best-practices: FastAPI Best Practices and Conventions we used at our startup
- Pythonの並列処理・並行処理をしっかり調べてみた #Python3 - Qiita
フロント
- 良いReactを書くことは凡事徹底だと考えている話 - カミナシ エンジニアブログ
- 【Next.js 16まで対応】もう置いていかれない!App Routerから理解する、速習Next.js📖 #初心者 - Qiita
エージェント・RAG・Context Engineering
- Building Effective AI Agents \ Anthropic
- How we built our multi-agent research system \ Anthropic
- Weekly AI Agents News! - Speaker Deck
- An Overview of Methods to Effectively Improve RAG Performance - Alibaba Cloud Community
- Paradigm Shifts of Eval in the Age of LLMs | by Lili Jiang | TDS Archive | Medium
- How we built our multi-agent research system \ Anthropic
- Context Engineering
- Effective context engineering for AI agents \ Anthropic
- How agents can use filesystems for context engineering
- Introducing advanced tool use on the Claude Developer Platform \ Anthropic
LLM要素技術
LLMアプリケーション・運用
その他
Github

(819→404)、-415となった。
【SHIROBAKO】後工程を考えて仕事するということ

この記事は、「#日めくりLayerX」と題して発信するブログリレーの2025年7月29日の記事として投稿しています。7月はAI・LLM事業部(Ai Workforce)の集中月間です!「私の◯◯愛を語る」というテーマに沿ってお送りします。
こんにちは。LayerX AI・LLM事業部のさいぺです。
突然ですが、皆さんはSHIROBAKOというアニメをご存知でしょうか。 毎クール20〜30本のアニメを見る生活を15年くらいしてきて、1000本以上アニメを見てきましたが、その中で最も好きな作品です。 全24話ですが、たぶん20周くらいしてます。劇場版も複数回足を運びました。 各種配信サイトで見れると思うので、未視聴の方はぜひ一度視聴してから続きをお読みください。
念のため説明すると、SHIROBAKOは2014年秋〜2015年春にかけて放送されたアニメで、アニメーション制作を題材としたアニメです。 アニメを作っているスタッフ陣が作る作品だけあって、現場の解像度が凄まじく高いですし、個人的には作品の至るところで「なぜその仕事をするのか」という問いかけが投げかけられ、その人その人の人生を感じられるところがとても好きです。
今回はその中でも、第7話「ネコでリテイク」と第8話「責めてるんじゃないからね」の話をするので、まずは8話まで視聴してきてください。
もしかしたら、まだ視聴されていない方もいるかもしれないので、簡単にあらすじを紹介すると、第7話と第8話では、原画担当の安原絵麻が大きな壁に直面するエピソードが展開されます。
絵麻は自らが経験したことがない猫の原画に挑戦しますが、描いたことがない猫、描いても描いても猫的ななにかにしかなりません。
後工程には作監、演出のチェックが控えていて、締切まで時間もありません。なんとか原画を提出しますが、作監の瀬川さんから全没のリテイクが出されます。
「今からこんな飛ばし方をするようでは困ると伝えてください」。
読んでいるだけで胃がきゅっとなるようなメールが届きます。
制作進行の宮森が、作監の瀬川さんの家を訪れ、絵麻の話になると、瀬川さんは「うまく伝わっているといいんだけど」と前置きして、次のようなことを言います。
きっともう少ししたら安原さんも普通にできるようになることなんだよ。自分の後の工程のことを考えて描くなんてことは。でも今はまだわからない。わからないからできない。ちょっとの違いなんだけどね
これめちゃくちゃ刺さりますよね〜〜〜〜〜〜〜
絵馬の描いた原画は、作監、演出のチェックを経て、原画と原画の間を間を埋める動画に回されます。つまり、原画がしっかりしていないと、動画の担当者は正しく動画を描くことができません。だから瀬川さんは「全部の線がなんとなくで、とりあえずなの。つまり、動画がものすごく拾いにくい線だってこと」と指摘していたのです。
自分の仕事を省みて
SHIROBAKOの放映当時、私はまだ学生でした。この瀬川さんの言葉も当時はしっくり来ていなかった気がします。でも今はすごく刺さります。
一人で業務が完結することなんてなくて、自分の仕事は後工程に繋がっています。
最初は自分の仕事に手いっぱいなものですが、気づいたら自分の前後の業務にも目がいくようになっていると思います。自分の書いたコードを誰がレビュー・QAしてデリバリーされていくのか、自分が作ったプレゼン資料をお客さまに送付したらお客さまの社内でどう展開されていくのか。そういうところに想像がいくようになった頃に、仕事がスムーズにまわるようになっていた気がします。
そして個人的に大事にしているのが、小さいお願いにも、後工程があることです。 月次のセキュリティ研修、出欠アンケート、月次の工数入力など、全社員が対応しないと次のステップに進めない業務があります。依頼された側としては、メインの業務が忙しくて、ついつい後回しにしちゃいがちなのですが、依頼した人は心苦しく思いながらリマインドしてるんだろうなぁと想像して、すぐやるようにしています。すぐやることで勝ち取れる信頼もあると思います。
SHIROBAKOは、学生の頃、新人の頃、仕事に慣れてきた頃、マネージャーになった頃とその時々で、違った視点をもらえる作品です。
ぜひ見てください!(三度目のリマインド)
2024年振り返り
2024年の振り返りとしてやったことをまとめる。
目標管理、Scrapboxは計測をやめた。
論文
scholar-inboxとXで流れてきた論文を、ChatGPTで要約したもの+本文のFigureを読むようになった。
Notionで管理するようにしたが11本が「済」となった。
書籍
- 書籍:
15冊(前年比-27冊 from 42冊)
漫画を読む時間を取れないまま一年が過ぎた。その他の本は毎朝10分の読書時間でコツコツと読んだ。 特に読んで良かった本は、HARD THINGS。
技術書
- データ匿名化手法 ―ヘルスデータ事例に学ぶ個人情報保護(Khaled El Emam,Luk Arbuckle/オライリージャパン)
- データ指向アプリケーションデザイン ―信頼性、拡張性、保守性の高い分散システム設計の原理(Martin Kleppmann/オライリージャパン)
- 型システム入門 −プログラミング言語と型の理論−(Benjamin C. Pierce/オーム社)
ビジネス書
- サイゼリヤの法則 なぜ「自分中心」をやめると、ビジネスも人生もうまくいくのか?(正垣 泰彦/KADOKAWA)
- 独創はひらめかない: 「素人発想、玄人実行」の法則(金出 武雄/日経BPマーケティング)
- ブリッツスケーリング(リード・ホフマン,クリス・イェ/日経BP)
- リーン・スタートアップ(エリック・リース/日経BP)
- THE MODEL(MarkeZine BOOKS) マーケティング・インサイドセールス・営業・カスタマーサクセスの共業プロセス(福田 康隆/翔泳社)
- HARD THINGS(ベン・ホロウィッツ/日経BP)
小説
- 三体(劉 慈欣/早川書房)
- 三体2 黒暗森林 上(劉 慈欣/早川書房)
- 三体2 黒暗森林 下(劉 慈欣/早川書房)
- 三体3 死神永生 上(劉 慈欣/早川書房)
- 三体3 死神永生 下(劉 慈欣/早川書房)
- 三体0【ゼロ】 球状閃電(劉 慈欣/早川書房)
- 暗黒星 (江戸川乱歩文庫)(江戸川乱歩/春陽堂書店)
- 怪人二十面相 (少年探偵・江戸川乱歩 文庫版 第 1巻)(江戸川乱歩/ポプラ社)
- 海にたゆたう一文字に(猿場つかさ)
記事
以下は今年読んでよかった記事。
業務上の都合で、Python/フロント(特にReact)に触れることが多く、その分野の記事を読んでいたが、本分野はRustなどに比べて良質な記事に当たる率が低いため、LLMに聞くことが多かった。
LLM/RAGは、会社のNewsletterでも配信されているもの+自分で見つけてきたもの(XやRSS)を結構な数読んだが、そのうち、良質なものを挙げた。
特によかったものだと、「What We Learned from a Year of Building with LLMs」は現場で手を動かした人の知見が凝縮されており、共感と学びの両面でとても良い記事だった。
また、プロンプトの書き方ではAnthropicの「Claude 3 Technical Dive」がよかった。Anthropicの記事は良質なものが多く、どれも一読の価値があるので、RSSに登録している。
Python
- 【初心者必見】Python中級者になるためのテクニック29選 #Python - Qiita
- pipとpipenvとpoetryの技術的・歴史的背景とその展望 - Stimulator
- Python の __init__.py とは何なのか #Python - Qiita
フロント
LLM
- LLM講座2024年「Day10. LLMの分析と理論」(後半パート) - Speaker Deck
- LLMOps : ΔMLOps - Speaker Deck
- LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide - Confident AI
- AOAI Dev Day LLMシステム開発 Tips集 - Speaker Deck
- 大規模言語モデルによる視覚・言語の融合/Large Vision Language Models - Speaker Deck
- Evaluating Large Language Model (LLM) systems: Metrics, challenges, and best practices | by Jane Huang | Data Science at Microsoft | Medium
- Short Musings on AI Engineering and "Failed AI Projects"
- What We Learned from a Year of Building with LLMs (Part I) – O’Reilly
- 行政における生成AIの適切な利活用に向けた技術検証の環境整備 - デジタル庁
- 生成AIの利用ガイドライン作成のための手引き|知的財産・IT・人工知能・ベンチャービジネスの法律相談なら【STORIA法律事務所】
- 社内文書検索&QAシステムの RAG ではないところ - Algomatic Tech Blog
- Claude 3 Technical Dive
- OpenAIのPrompt Engineering Guideでより良い結果を得るプロンプトエンジニアリングを学ぶ
RAG
- RAG入門: 精度改善のための手法28選 #Python - Qiita
- RAGのSurvey論文からRAG関連技術を俯瞰する - 元生技のデータサイエンティストのメモ帳
- Retrieval Augmented Generation (RAG) for LLMs | Prompt Engineering Guide
- Chunking Strategies for LLM Applications | Pinecone
- RAGの実装戦略まとめ #Python - Qiita
その他
- I spent 8 hours learning Parquet. Here’s what I discovered | by Vu Trinh | Data Engineer Things
- 【スライド約300枚】ベンチャーマネージャーのマニュアル|長村禎庸@EVeM
- 令和時代の API 実装のベースプラクティスと CSRF 対策 | blog.jxck.io
- 開発者向け MySQL 入門 / MySQL 101 for Developers - Speaker Deck
- 人は、スランプの時のみ成長する – 前田ヒロ
- メルカリ 小泉さんからのエグい学び|Shota Horii
- エンジニアはどのようにドメインにダイブできるか - Speaker Deck
Github
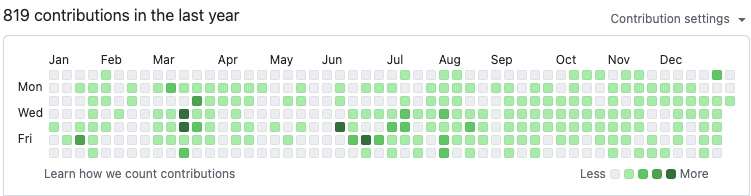
昨年の振り返り記事ではprivate contributionが含められていなかったが、今年は含めた。含めた上で(668→819)、+151となった。
2023年振り返り
2023年の振り返りとしてやったことをまとめる。
目標管理
例年通り、四半期ごとの見直し、月次の進捗確認で運用をした。 1,4,7,10月に目標の見直しを行い次四半期の目標を立て、2,3,5,6,8,9,11,12月は進捗を確認する運用。ただし今年は目標管理のモチベーションが低く、あまり見直しはしなかった。新しい目標を達成するというよりは、淡々と、コツコツと積み上げた形になった。昨年秋に始めた朝読書を一日も欠かさなかったし、完全に習慣化した。
論文
1月
- Culnane, Chris, Benjamin IP Rubinstein, and Vanessa Teague. "Health data in an open world." arXiv preprint arXiv:1712.05627 (2017). https://arxiv.org/pdf/1712.05627.pdf
- Narayanan, Arvind. "An adversarial analysis of the reidentifiability of the heritage health prize dataset." Unpublished manuscript (2011). https://www.cs.princeton.edu/~arvindn/publications/heritage-health-re-identifiability.pdf
4月
- Li, Ninghui, Wahbeh Qardaji, and Dong Su. "On sampling, anonymization, and differential privacy or, k-anonymization meets differential privacy." Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security. 2012. https://arxiv.org/pdf/1101.2604.pdf
- Li, Ninghui, Wahbeh H. Qardaji, and Dong Su. "Provably private data anonymization: Or, k-anonymity meets differential privacy." CoRR, abs/1101.2604 49 (2011): 55. https://www.cerias.purdue.edu/assets/pdf/bibtex_archive/2010-24-report.pdf
ざっと読み、抜粋読み
1月
- Asghar, Hassan Jameel, Paul Tyler, and Mohamed Ali Kaafar. "Differentially private release of public transport data: The opal use case." arXiv preprint arXiv:1705.05957 (2017). https://arxiv.org/pdf/1705.05957.pdf
- Sweeney, Latanya. "Weaving technology and policy together to maintain confidentiality." The Journal of Law, Medicine & Ethics 25.2-3 (1997): 98-110. https://latanyasweeney.org/JLME.pdf
4月
- Ghazi, Badih, et al. "Algorithms with More Granular Differential Privacy Guarantees." arXiv preprint arXiv:2209.04053 (2022). https://arxiv.org/pdf/2209.04053.pdf
- Desfontaines, Damien, et al. "Differential privacy with partial knowledge." arXiv preprint arXiv:1905.00650 (2019). https://arxiv.org/pdf/1905.00650.pdf
- Li, Ninghui, Wahbeh Qardaji, and Dong Su. "On sampling, anonymization, and differential privacy or, k-anonymization meets differential privacy." Proceedings of the 7th ACM Symposium on Information https://arxiv.org/pdf/1101.2604.pdf
5月
- Ohm, Paul. "Broken promises of privacy: Responding to the surprising failure of anonymization." UCLA l. Rev. 57 (2009): 1701. http://www.lawlib.zju.edu.cn/attachments/file/20201118/20201118174834_66017.pdf
- Ohm, Paul. "Sensitive information." S. Cal. L. Rev. 88 (2014): 1125. https://southerncalifornialawreview.com/wp-content/uploads/2018/01/88_1125.pdf
6月
- Syomantak Chaudhuri and Thomas A. Courtade. "Mean Estimation Under Heterogeneous Privacy: Some Privacy Can Be Free" arXiv preprint arXiv:2305.09668 (2023). https://arxiv.org/pdf/2305.09668.pdf
読む本数が少なすぎるが、朝読書と違って習慣化していないのがよくない。週末は趣味の活動もあるのでうまくバランスを取りながら、数分でもいいのでコツコツと読む習慣を作るのが来年のアクション。
書籍
- 漫画を含めた書籍:
42冊(前年比+13冊 from 29冊)
特に読んで良かった本はデータ指向アプリケーションデザイン、考える技術・書く技術、イシューからはじめよ、ナチスは「良いこと」もしたのか? 特に『ナチスは「良いこと」もしたのか?』については、歴史研究における事実/解釈/意見の三層構造に関する考え方が述べられるまえがきでもいいので、必読であった。
技術書
- データ匿名化手法 ―ヘルスデータ事例に学ぶ個人情報保護(Khaled El Emam,Luk Arbuckle/オライリージャパン)
- データ指向アプリケーションデザイン ―信頼性、拡張性、保守性の高い分散システム設計の原理(Martin Kleppmann/オライリージャパン)
- 型システム入門 −プログラミング言語と型の理論−(Benjamin C. Pierce/オーム社)
ビジネス書・趣味
- 解像度を上げる――曖昧な思考を明晰にする「深さ・広さ・構造・時間」の4視点と行動法(馬田隆明/英治出版)
- 新版 考える技術・書く技術 問題解決力を伸ばすピラミッド原則(バーバラ・ミント/ダイヤモンド社)
- イシューからはじめよ――知的生産の「シンプルな本質」(安宅和人/英治出版)
- スタッフエンジニア マネジメントを超えるリーダーシップ(Will Larson/日経BP)
- 10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く (Informatics &IDEA)(青木峰郎/SBクリエイティブ)
- ビジネスダッシュボード 設計・実装ガイドブック 成果を生み出すデータと分析のデザイン(トレジャーデータ,池田 俊介,藤井 温子,櫻井 将允,花岡 明/翔泳社)
- おそろしいビッグデータ 超類型化AI社会のリスク(山本龍彦/朝日新書/朝日新聞出版)
- 検証 ナチスは「良いこと」もしたのか?(小野寺 拓也,田野 大輔/岩波ブックレット 1080/岩波書店)
- ヒトラーの脱走兵-裏切りか抵抗か、ドイツ最後のタブー(對馬達雄/中公新書/中央公論新社)
- 批評理論入門―『フランケンシュタイン』解剖講義 (廣野由美子/中公新書/中央公論新社)
- 夏への扉(ロバート・A. ハインライン/ハヤカワ文庫SF/早川書房)
- 孤島の鬼(江戸川乱歩/創元推理文庫―現代日本推理小説叢書/東京創元社)
- 流行作家の死(野村胡堂/ゴマブックス)
- 倒れるときは前のめり(有川ひろ/角川文庫//KADOKAWA)
- 倒れるときは前のめり ふたたび(有川ひろ/角川文庫//KADOKAWA)
- アンマーとぼくら(有川ひろ/講談社文庫/講談社)
- イマジン?(有川ひろ/幻冬舎文庫 あ 34-8/幻冬舎)
記事
昨年に引き続き、英語記事に目を通すようになった。readingスキルの伸びを感じるが、まだ読むのが遅いし、疲れていると英文が頭に入ってこない。 以下は今年読んでよかった記事。
- 強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) | PPT
- LLM Fine-Tuning (東大松尾研LLM講座 Day5資料) - Speaker Deck
- Transformer / Vision and Languageの基礎 - Speaker Deck
- 大規模言語モデルの驚異と脅威 - Speaker Deck
- 宮脇+'23 - Prompt Engineering サーベイ - Speaker Deck
- Retrieval-based LM (RAG system) ざっくり理解する - Speaker Deck
- NLPとVision-and-Languageの基礎・最新動向 (1) / DEIM Tutorial Part 1: NLP - Speaker Deck
- NLPとVision-and-Languageの基礎・最新動向 (2) / DEIM Tutorial Part 2 Vision-and-Language - Speaker Deck
- Federated Learning Tutorial (IBIS 2022) - Speaker Deck
- 進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~|知的財産・IT・人工知能・ベンチャービジネスの法律相談なら【STORIA法律事務所】
- ChatGPTなど生成AIによる個人情報の開示 | 調査研究/ブログ | 三井物産セキュアディレクション株式会社
- Google の新たな生成AIモデル Gemini を技術的観点で解説 - Platinum Data Blog by BrainPad
- dbt Labs のベストプラクティス全部違反してみた。そして dbt project evaluator を使って全部直してみた。
- なぜETLではなくELTが流行ってきたのか #ポエム - Qiita
- 差分プライバシーによるクエリ処理の基本・実践・最前線 - Speaker Deck
- Personalization Improves Privacy-Accuracy Tradeoffs in Federated Learning - Speaker Deck
- 高木浩光さんに訊く、個人データ保護の真髄 ——いま解き明かされる半世紀の経緯と混乱 - Cafe JILIS
- ニッポンの教育ログを考える——プライバシーフリーク・カフェ#16(後編) - Cafe JILIS
- 個人データ保護の法目的の観点から導かれる個人データ二次利用の正当性要件について, 2022年11月7日規制改革推進会議 医療・介護・感染症対策WG, 一般財団法人 情報法制研究所 副理事長 高木浩光
- 医療データ利活用の課題
- 社内用GitHub Actionsのセキュリティガイドラインを公開します | メルカリエンジニアリング
- 「私考える人、あなた作業する人」を越えて、プロダクトマネジメントがあたりまえになるチームを明日から実現していく方法/product management rsgt2023 - Speaker Deck
- 事業計画の達成はなぜ大切なのか|福島良典 | LayerX
- Kaggleで世界トップレベルになるための思考法。Grandmaster小野寺和樹の頭の中 - Findy Engineer Lab - ファインディエンジニアラボ
- “超”分析の実践:業務効率を改善する – ファミレスチェーンの利益率を向上させるには- - Kearney
- 菊池寛 私の日常道徳
- SKBパケット選抜総選挙 〜 僕たちは誰について行けばいい? 〜 /osc21do - Speaker Deck
- Amazon S3の脆弱な利用によるセキュリティリスクと対策 - Flatt Security Blog
- node_modulesの問題点とその歴史 npm, yarnとpnpm
- AI 時代のコードの書き方, あるいは Copilot に優しくするプロンプターになる方法
- URL バーの表示の変遷 | blog.jxck.io
- ブラウザでリロードしながらキャッシュの挙動を確認してる全ての開発者へ | blog.jxck.io
- 「議論だけ」のカンファレンスの作り方 | blog.jxck.io
- Recursion in SQL Explained Visually | by Denis Lukichev | The Startup | Medium
- Who Owns the Generative AI Platform? | Andreessen Horowitz
- The next big step forwards for analytics engineering
- Google Research, 2022 & beyond: ML & computer systems – Google Research Blog
- A Deep Dive Into Google BigQuery Architecture: How It Works | Panoply
- Inside Capacitor, BigQuery’s next-generation columnar storage format | Google Cloud Blog
- Building a Document-based Question Answering System with LangChain, Pinecone, and LLMs like GPT-4 and ChatGPT
Github
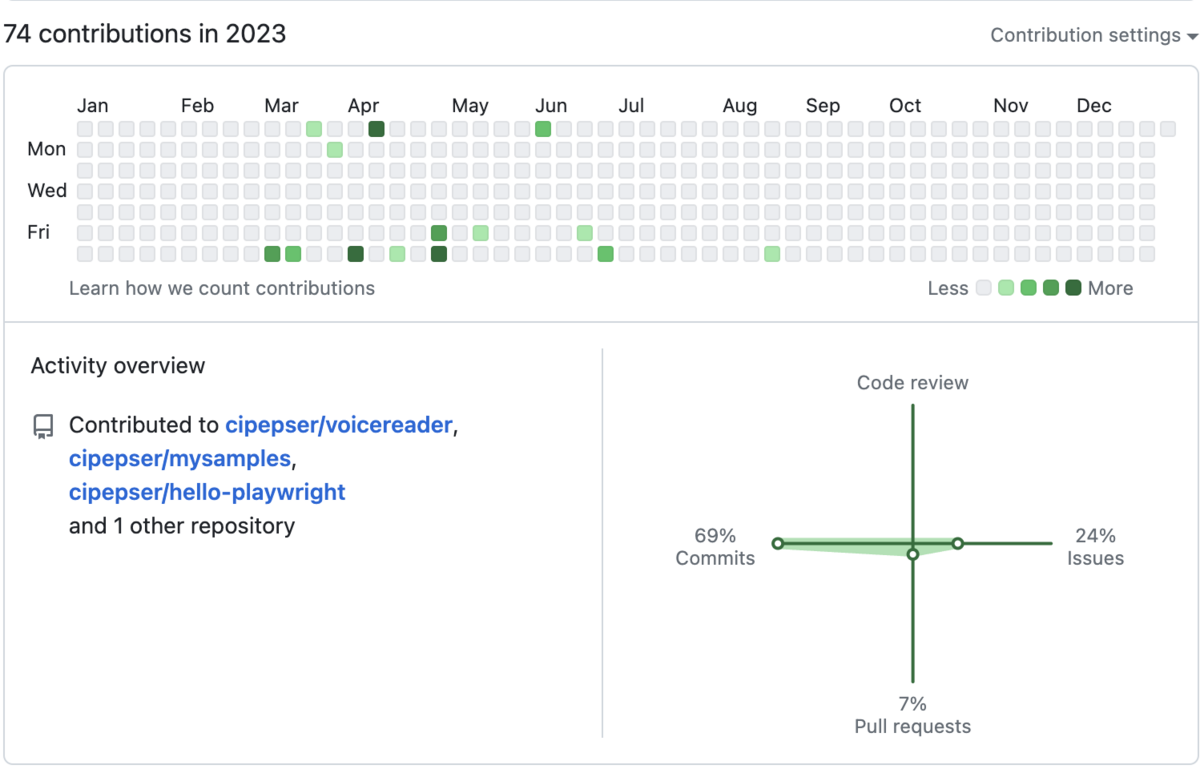
昨年の17 contributionsに対して、+57となった。
Scrapbox
1611→1764pages
2022年振り返り
2022年の振り返りとしてやったことをまとめる。
目標管理
例年通り、四半期ごとの見直し、月次の進捗確認で運用をした。 1,4,7,10月に目標の見直しを行い次四半期の目標を立て、2,3,5,6,8,9,11,12月は進捗を確認する運用。
大項目として以下4つを設け、それぞれ中項目の目標を立てた。中項目をさらに細分化して、四半期ごとに小項目での目標管理をした。括弧内は中項目のうち、達成できた数を記載。
- 読書(2/3)
- 健康(1/2)
- 英語(1/1)
- 趣味(2/5)
論文
1月
Amin, K., Dick, T., Kulesza, A., Medina, A. M., & Vassilvitskii, S. (2019). Differentially private covariance estimation. Advances in Neural Information Processing Systems, 32(NeurIPS).
Stadler, T., Oprisanu, B., & Troncoso, C. (2020). Synthetic Data -- Anonymisation Groundhog Day.
Rogers, R., Subramaniam, S., Peng, S., Durfee, D., Lee, S., Kancha, S. K., Sahay, S., & Ahammad, P. (2020). LinkedIn’s Audience Engagements API: A Privacy Preserving Data Analytics System at Scale. http://arxiv.org/abs/2002.05839
2月
- Cao, Yang and Yoshikawa, Masatoshi and Xiao, Yonghui and Xiong, Li, Quantifying differential privacy under temporal correlations, Data Engineering (ICDE), 2017 IEEE 33rd International Conference on, 821--832, 2017.
3月
- Kareem Amin, Jennifer Gillenwater, Matthew Joseph, Alex Kulesza, Sergei Vassilvitskii. "Plume: Differential Privacy at Scale" arXiv preprint arXiv:2201.11603 (2022).
4月
- Cangialosi, Frank, et al. "Privid: Practical, privacy-preserving video analytics queries." arXiv preprint arXiv:2106.12083 (2021). https://www.usenix.org/system/files/nsdi22-paper-cangialosi.pdf
5月
- Chaudhuri, Kamalika, Jacob Imola, and Ashwin Machanavajjhala. "Capacity bounded differential privacy." Advances in Neural Information Processing Systems 32 (2019). https://proceedings.neurips.cc/paper/2019/file/04df4d434d481c5bb723be1b6df1ee65-Paper.pdf
6月
Adam, Nabil R., and John C. Worthmann. "Security-control methods for statistical databases: a comparative study." ACM Computing Surveys (CSUR) 21.4 (1989): 515-556. https://dl.acm.org/doi/pdf/10.1145/76894.76895
Rowe, Neil C. "Diophantine inferences from statistical aggregates on few-valued attributes." 1984 IEEE First International Conference on Data Engineering. IEEE, 1984.
7月
Denning, Dorothy Elizabeth Robling. Cryptography and data security. Vol. 112. Reading: Addison-Wesley, 1982. https://core.ac.uk/download/pdf/36729637.pdf (6.1-6.4)
Matsumoto, Marin, et al. "Measuring Lower Bounds of Local Differential Privacy via Adversary Instantiations in Federated Learning." arXiv preprint arXiv:2206.09122 (2022). https://arxiv.org/pdf/2206.09122.pdf
Dwork, Cynthia, Nitin Kohli, and Deirdre Mulligan. "Differential privacy in practice: Expose your epsilons!." Journal of Privacy and Confidentiality 9.2 (2019). https://par.nsf.gov/servlets/purl/10217360
9月 - Kifer, Daniel, and Ashwin Machanavajjhala. "No free lunch in data privacy." Proceedings of the 2011 ACM SIGMOD International Conference on Management of data. 2011. https://www.cse.psu.edu/~duk17/papers/nflprivacy.pdf
12月 - El Emam, Khaled, et al. "A systematic review of re-identification attacks on health data." PloS one 6.12 (2011): e28071. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0028071
ざっと読み、抜粋読み
1月
- Desfontaines, D., Voss, J., Gipson, B., & Mandayam, C. (2022). Differentially private partition selection. Proceedings on Privacy Enhancing Technologies, 2022(1), 339–352. https://doi.org/10.2478/popets-2022-0017
3月
- Asi, Hilal, John Duchi, and Omid Javidbakht. "Element level differential privacy: The right granularity of privacy." arXiv preprint arXiv:1912.04042 (2019).
4月
bo Wang, Hongtao Li, Yina Guo, Xiaoyu Ren, "An Ecient Location Privacy Protection Method for Location-Based Services based on Differential Privacy", Research Square, 2022 . https://assets.researchsquare.com/files/rs-1504387/v1_covered.pdf?c=1649083710
Gorka Abad, Stjepan Picek, V´ıctor Julio Ram´ırez-Dur´an, Aitor Urbieta, "On the Security & Privacy in Federated Learning". arXiv preprint arXiv:2112.05423 (2022). https://arxiv.org/pdf/2112.05423.pdf
Yeom, Samuel, et al. "Privacy risk in machine learning: Analyzing the connection to overfitting." 2018 IEEE 31st computer security foundations symposium (CSF). IEEE, 2018. https://arxiv.org/pdf/1709.01604.pdf
Song, Liwei, and Prateek Mittal. "Systematic evaluation of privacy risks of machine learning models." 30th USENIX Security Symposium (USENIX Security 21). 2021. https://www.usenix.org/system/files/sec21-song.pdf
Nasr, Milad, Reza Shokri, and Amir Houmansadr. "Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning." 2019 IEEE symposium on security and privacy (SP). IEEE, 2019. https://www.comp.nus.edu.sg/~reza/files/Shokri-SP2019.pdf
Shokri, Reza, et al. "Quantifying location privacy." 2011 IEEE symposium on security and privacy. IEEE, 2011. https://orca.cardiff.ac.uk/37912/1/Quantifying_Location_Privacy.pdf
Ateniese, Giuseppe, et al. "Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers." International Journal of Security and Networks 10.3 (2015): 137-150. https://arxiv.org/pdf/1306.4447.pdf
Murakonda, Sasi Kumar, and Reza Shokri. "Ml privacy meter: Aiding regulatory compliance by quantifying the privacy risks of machine learning." arXiv preprint arXiv:2007.09339 (2020). https://arxiv.org/pdf/2007.09339.pdf
Tseng, Wei-Cheng, Wei-Tsung Kao, and Hung-yi Lee. "Membership Inference Attacks Against Self-supervised Speech Models." arXiv preprint arXiv:2111.05113 (2021).
5月
Tramèr, Florian, et al. "Stealing Machine Learning Models via Prediction {APIs}." 25th USENIX security symposium (USENIX Security 16). 2016. https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf
Salem, Ahmed, et al. "Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models." arXiv preprint arXiv:1806.01246 (2018). https://arxiv.org/pdf/1806.01246.pdf
Lindell, Yehuda, and Benny Pinkas. "Privacy preserving data mining." Journal of cryptology 15.3 (2002). https://link.springer.com/content/pdf/10.1007/s00145-001-0019-2.pdf
Canny, John. "Collaborative filtering with privacy via factor analysis." Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. 2002. https://www.researchgate.net/profile/John-Canny/publication/3948694_Collaborative_Filtering_with_Privacy/links/5581e03708ae6cf036c16ff4/Collaborative-Filtering-with-Privacy.pdf
Stewart, Kathy A., and Albert H. Segars. "An empirical examination of the concern for information privacy instrument." Information systems research 13.1 (2002): 36-49. https://www.researchgate.net/profile/Albert-Segars-2/publication/220079710_An_Empirical_Examination_of_the_Concern_for_Information_Privacy_Instrument/links/5be32f36299bf1124fc2da16/An-Empirical-Examination-of-the-Concern-for-Information-Privacy-Instrument.pdf
Vaidya, Jaideep, and Chris Clifton. "Privacy-preserving k-means clustering over vertically partitioned data." Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 2003. https://www.cerias.purdue.edu/assets/pdf/bibtex_archive/2003-47.pdf
Lo Piano, S. (2020). Ethical principles in machine learning and artificial intelligence: cases from the field and possible ways forward. Humanities and Social Sciences Communications, 7(1), 1–7. https://doi.org/10.1057/s41599-020-0501-9 https://www.nature.com/articles/s41599-020-0501-9.pdf
Choquette-Choo, Christopher A., et al. "Label-only membership inference attacks." International Conference on Machine Learning. PMLR, 2021. https://arxiv.org/pdf/2007.14321.pdf
Kifer, Daniel, and Ashwin Machanavajjhala. "Pufferfish: A framework for mathematical privacy definitions." ACM Transactions on Database Systems (TODS) 39.1 (2014): 1-36. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.436.2576&rep=rep1&type=pdf
Damien Desfontaines, and Bal´azs Pej´o, "SoK: Differential Privacies A taxonomy of differential privacy variants and extensions", 2019. https://arxiv.org/pdf/1906.01337.pdf
Josh Smith, et al. "Making the Most of Parallel Composition in Differential Privacy", Privacy Enchancing Technologies Symposium (PETS) 2022. https://petsymposium.org/2022/files/papers/issue1/popets-2022-0013.pdf
6月
Cormode, Graham, et al. "Empirical privacy and empirical utility of anonymized data." 2013 IEEE 29th International Conference on Data Engineering Workshops (ICDEW). IEEE, 2013. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.591.8092&rep=rep1&type=pdf
小栗秀暢. "プライバシー保護データ流通のための匿名化手法." システム/制御/情報 63.2 (2019): 51-57. https://www.jstage.jst.go.jp/article/isciesci/63/2/63_51/_pdf
高橋翼. 系列データの匿名化に関する研究. Diss. 筑波大学 (University of Tsukuba), 2014. https://core.ac.uk/download/pdf/56657868.pdf
Ayala-Rivera, Vanessa, et al. "A systematic comparison and evaluation of k-anonymization algorithms for practitioners." Transactions on data privacy 7.3 (2014): 337-370. https://researchrepository.ucd.ie/handle/10197/9109
Dwork, Cynthia, et al. "Calibrating noise to sensitivity in private data analysis." Theory of cryptography conference. Springer, Berlin, Heidelberg, 2006. https://link.springer.com/content/pdf/10.1007/11681878_14.pdf
Nicholas Carlini, et al. "(Certified!!) Adversarial Robustness for Free!" arXiv preprint arXiv:2206.10550 (2022). https://arxiv.org/pdf/2206.10550.pdf
7月
U.S. Department of Commerce (1978), Statistical Policy Working Paper 2: Report on Statistical Disclosure and DisclosureAvoidance Techniques, U.S. Government Printing Office, Washington, DC. https://nces.ed.gov/fcsm/pdf/spwp2.pdf
Kellaris, Georgios, et al. "Differentially private event sequences over infinite streams." Proceedings of the VLDB Endowment 7.12 (2014): 1155-1166. http://people.csail.mit.edu/stavrosp/papers/vldb2014/VLDB14_WDP.pdf
書籍
- 漫画を含めた書籍:
29冊(前年比-34冊※)
※今年から雑誌は含めないことにした
技術書
- なし
ビジネス書・趣味
- 映画を早送りで観る人たち~ファスト映画・ネタバレ――コンテンツ消費の現在形~ (光文社新書)
- オルレアンの少女 (岩波文庫 赤 410-10)
- ジャンヌ・ダルク 超異端の聖女 (講談社学術文庫)
- プロジェクト・ヘイル・メアリー 上
- プロジェクト・ヘイル・メアリー 下
- 人間ぎらい (新潮文庫)
- 令和2年改正 個人情報保護法の実務対応-Q&Aと事例-
記事
昨年に引き続き、あまり記事を読んでいない。ただし、英語記事に目を通すようになった。 以下は今年読んでよかった記事。
- ブルシットプロダクトからチームを守れ! 「顧客が本当に必要だったもの」をいかに追求しつづけるか /bullshit product rsgt2022 - Speaker Deck
- インシデントレスポンスを自動化で支援する - Slack Bot で人機一体なセキュリティ対策を実現する | CloudNative Days Tokyo 2021
- さようなら、謎の数値ズレ。dbtを活用してデータ品質管理をはじめよう | by Sotaro Tanaka | Medium
- 「売れない営業の11の特徴」は売れる営業への道標|野村修平|note
- 不況下の事業計画の見直し - 攻めるべきスタートアップ、守るべきスタートアップ|原健一郎 | Kenichiro Hara|note
- HTTP 関連 RFC が大量に出た話と 3 行まとめ | blog.jxck.io
- 差分プライバシーによるデータ活用最前線 - Speaker Deck
- 死なないために - 宮田昇始のブログ
- sigstoreによるコンテナイメージやソフトウェアの署名 - knqyf263's blog
- 世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説(前編)。DevOps Days Tokyo 2022 - Publickey
- HPKE とは何か | blog.jxck.io
- 不況下での財務的な経営の舵取りについて|SatoshiYamada|note
- みずほ銀行システム障害に学ぶ | 川口耕介のブログ
- ソフトウェアエンジニアとしての姿勢と心構え / Software Engineer's Survival Guide - Speaker Deck
- 機械学習でハタラクをバクラクにするために LayerX に入社しました #LayerX|yu-ya4|note
- XMLHttpRequest とはなんだったのか | blog.jxck.io
- なぜETLではなくELTが流行ってきたのか - Qiita
- 生成AIが創れる世界|やまかず|note
Github
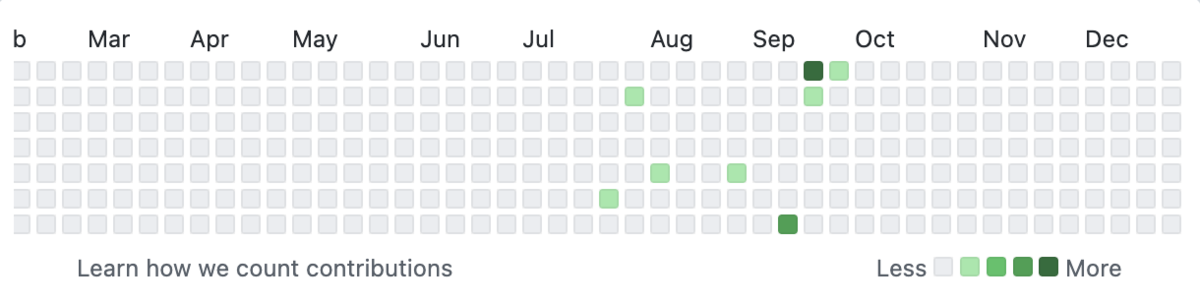
昨年の1,249 contributionsに対して、-1,231となった。
Githubで管理していないコードやクエリを書く機会が多かったため。
Scrapbox
1376→1611pages
dbtを使い始めて数ヶ月が経った雑感
この記事は dbt Advent Calendar 2022 の25日目の記事です。dbtを使い始めて数ヶ月ほど経過したので、これまでの所感を書きます。
はじめに
dbt (data build tool) はデータ処理変換を担うフレームワークです[1]。データエンジニアリングにおいて重要なデータ分析の品質保証をデータモデルの構築、テスト、ドキュメンテーションをいった要素で実現します。とりわけDWHに統合して使われることが意図されており、ETLにおけるTransferの役割を実現してくれます。
Coalece2022の[3]のセッションでも語られていますが、この25年間、ストレージコストが低下したことや、よりデータへのアクセスが容易になったなったことで、足元ではすべての変換を一つのDWHで行うETLからELTへといった流れも出てきました。この流れによって、よりdbtが真価を発揮しやすい環境が整ってきたと言えると思います。
チームでデータ分析
個人的に感じているdbtの本質的な価値はデータ分析のプロセスの管理と効率化です。
特に現代データ分析においてはデータエンジニア一人で分析業務を担い切ることは少なく、チーム・組織として分析を高度化し、顧客により大きな価値を届けられるようなデータ分析プロセスの実現とその管理が求められます。
私が従事している業務でも、構造が同一のクエリを何度も何度も手書きし、それを都度レビューするといったプロセスに課題を感じてしました(何度同じクエリを書くのかといった開発者視点での課題であったり、ほぼ同じクエリだからという心理状態によるレビュー品質の低下といったレビュワー・チーム視点での課題など)。
SQLをチームで書いた経験のある方ならわかると思いますが、クエリのコードレビューには大きな集中力を要します。CTEに分解しながら手元で小さなダミーデータを用意したりしながら実行し、クエリ全体としても問題ないということを考えるレビューは大きな労力です。
弱い心を前に浅いレビューで通してしまったりすることもあり、それが積み重なると属人的なクエリのできあがりです。さらに大きなクエリは依存関係も複雑になりがちで、どの中間テーブルを使うのか、その中間テーブルの品質がどれくらい保証されているのかといった課題が発生しがち(「この中間テーブルって最新ですか?」とテーブル作成者にヒアリングして回ったり)で、結果として品質の低いデータ分析結果を顧客に届けることになりかねません。データやファクトに基づく意思決定を誤った方向に導き、ビジネス上の損失や信頼を毀損する結果にも繋がりえます。
ここまでの話を整理すると、以下3つに課題を感じていました。
- 依存関係が複雑化し、認知的負荷が大きい
- 中間テーブルの各カラムが満たすべき制約がわからず、設計が見えない
- 同じようなクエリを都度レビューしなくてはいけない
dbtでの解決
依存関係が複雑化し、認知的負荷が大きい
この課題については、シンプルに dbt docs コマンドで可視化してくれることが、依存関係の把握を助けてくれます。Coalece2022の[4]のセッションではモデリングパターンを以下4つに分類し、これをリファクタリングするワークショップの様子が届けられていますが、可視化されるとどのパターンに分類されるのかがひと目で分かるので、改善へのステップがエスカレーターになっていることにもdbtというプロダクトの強さを感じます。
- ソースから直接データをjoinしている
- 同じデータセットから何度もjoinしている
- 依存の依存をjoinしている
- 成果物にソースを使っている

([4]の発表中より引用)
中間テーブルの各カラムが満たすべき制約がわからず、設計が見えない
テストが書けることで各カラムにどういった制約が見えるようになります。
unique 、not_null 、accepted_values 、relationships (そのカラムが他テーブルに存在するreferential integrityの担保)といったテストが標準 [5]で用意されていますし、これら標準機能で手が届かないようなテストもdbt-utils [6]に解決策が用意されています(複数カラムを跨ったuniquenessを保証したいときに unique_combination_of_columns などをよく利用します)。これらも実態としてはJinjaマクロなので、さらに物足りないときは自作でき十分な柔軟性を備えていると思います。
そして[2] は、data profilingやdata contract、data pipelinesの文脈での話にはなりますが、データ品質問題に対するアプローチとして以下の流れを提案しています。
- 品質の低いデータを特定する(異常値など)
- 許容する値を規定する
- データパイプライン上で、顧客に届く前に、エラーを補足する
dbtのテストはこの2.と3.に対しての保証と見ることもできるでしょう。
個人的にはこれに加えてテストを見れば各カラムにどのような制約が掛かっているのか(どういう設計なのか)が理解しやすく、テスト自体がドキュメンテーションになる点も気に入っています。
同じようなクエリを都度レビューしなくてはいけない
dbtのデータ変換はSQLとJinjaを組み合わせて実現されています[7]。Jinja[8]はPython-likeなシンタックスを持つテンプレートエンジンです。dbtで利用できるマクロもJinjaを使って生成できるため、複雑なクエリを汎用化し、再利用性を得ることができます。これによって算術演算が多い等の低レベルのクエリや注意深いレビューが必要なクエリなどを一度十分なレビューをすることで品質を保ったまま再利用可能なクエリを生成することができます。
このJinjaマクロを使った方法で一定の解決をみているものの、マクロのメンテナンスコストも無視できないものだと感じています。モデリングによる解決とマクロでの解決の両軸をどのようにバランスさせていくかは個人的にも興味が向いている点です。「同じようなクエリを都度レビューしなくてはいけない」という課題で対象としているクエリを分解すると「ロジックが共通であるクエリ」と「低レベルのクエリ」があるように感じているので、前者はモデリング+マクロによる解決、後者はdbt Core v1.3で導入されたPython models [9] による解決が望ましいのではとも思え、このあたりは考えを深めていきたい論点になります(まだ視聴できていないのですが、Coalece2022でのなぜPythonを第二言語としたのかについてのセッション[10]で話されていたりしないかも気になっています)。
最後に
簡単ではありますが、dbtを使い始めて数ヶ月の雑感でした。まだまだ知らないことだらけではありますが、使い始める前に感じていた課題が解消されていてdbtの恩恵を感じています。何より複雑なSQLを書いていたときに比べて、構造化ができている点、しっかりと管理でき品質保証されている点に安心感を持って開発を進めることができています。dbt Advent Calendar 2022 を拝見していても、初めて知ることも多かったり、エコシステム自体が大きく成長しようとしている兆しも感じるところで、2023年もどのように変わっていくのか非常に楽しみな技術です。
References
- [1] DevelopersIO 2022 データ変換パイプラインをdbtでレベルアップ #devio2022 | DevelopersIO
- [2] 3 Methods to Solve Your Data Quality Problem Using Python | by Sarah Floris | Python in Plain English
- [3] Babies and bathwater: Is Kimball still relevant?
- [4] Buried Alive: Refactoring an inherited project
- [5] Tests | dbt Developer Hub
- [6] dbt-labs/dbt-utils: Utility functions for dbt projects.
- [7] Jinja and macros | dbt Developer Hub
- [8] Jinja — Jinja Documentation (3.1.x)
- [9] Python models | dbt Developer Hub
- [10] Announcing dbt's Second Language: When and Why We Turn to Python
2021年振り返り
2021年の振り返りとしてやったことをまとめる。
目標管理
昨年に引き続き、四半期ごとの見直し、月次の進捗確認で運用をした。 1,4,7,10月に目標の見直しを行い次四半期の目標を立て、2,3,5,6,8,9,11,12月は進捗を確認する運用。
大項目として以下5つを設け、四半期ごとに小項目での目標管理をした。括弧内は小項目のうち、達成できた数を記載(次四半期で取り返せたものは達成扱い)。
- 技術(4/12)
- 読書(10/17)
- 健康(6/8)
- 英語(5/7)
- 趣味(5/11)
- 資産運用(2/5)
全体として53%の達成率だった。昨年の 65% に対して大きく減ってしまった。
毎月の目標見直しで「またこの目標に着手できなかった」となることが多く、目標管理自体のモチベが大きく下がる要因となっていたし、精神的な重荷にもなっていた。
来年は以下を意識する。
- 目標の取捨選択
- 目標への取り組みを行う時間を何処で取るのかまで含めて計画
論文
日本語の論文や金融機関のレポート、決算資料も読んでいるが、ここでは含めない。
- Christodorescu, Mihai, et al. "Towards a Two-Tier Hierarchical Infrastructure: An Offline Payment System for Central Bank Digital Currencies." arXiv preprint arXiv:2012.08003 (2020).
- Han, Shujie, et al. "An In-Depth Study of Correlated Failures in Production SSD-Based Data Centers." 19th {USENIX} Conference on File and Storage Technologies ({FAST} 21). 2021.
- Bahmani, Raad, et al. "{CURE}: A Security Architecture with CUstomizable and Resilient Enclaves." 30th {USENIX} Security Symposium ({USENIX} Security 21). 2021.
- Vasily A. Sartakov, et al. "Spons & Shields: practical isolation for trusted execution" The 17th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments. 2021.
- van Schaik, Stephan, et al. "CacheOut: Leaking data on Intel CPUs via cache evictions." 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021.
- Alexander Sprogø Banks, "Remote Attestation: A Literature Review", 2021.
- Purnal, Antoon, et al. "Systematic analysis of randomization-based protected cache architectures." 42th IEEE Symposium on Security and Privacy. Vol. 5. 2021.
- Lefeuvre, Hugo, et al. "FlexOS: making OS isolation flexible." Proceedings of the Workshop on Hot Topics in Operating Systems. 2021.
- Nider, Joel, and Alexandra Fedorova. "The last CPU." Proceedings of the Workshop on Hot Topics in Operating Systems. 2021.
- Lillian Tsai, et al. "Privacy Heroes Need Data Disguises" Proceedings of the Workshop on Hot Topics in Operating Systems. 2021.
- Feng, Erhu, et al. "Scalable Memory Protection in the PENGLAI Enclave." 15th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 21). 2021.
- Kumar, Sam, David E. Culler, and Raluca Ada Popa. "{MAGE}: Nearly Zero-Cost Virtual Memory for Secure Computation." 15th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 21). 2021.
- Farke, Florian M., et al. "Are Privacy Dashboards Good for End Users? Evaluating User Perceptions and Reactions to Google's My Activity." 30th USENIX Security Symposium (USENIX Security 21). 2021.
- Julie Haney, et al. "\"It's the Company, the Government, You and I\": User Perceptions of Responsibility for Smart Home Privacy and Security", 30th USENIX Security Symposium (USENIX Security 21). 2021.
- Messing, Solomon, et al. "State, Bogdan; Wilkins, Arjun, 2020,” Facebook Privacy-Protected Full URLs Data Set”.", 2020.
- Chanyaswad, Thee, et al. "Mvg mechanism: Differential privacy under matrix-valued query." Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications S, 2018.
- Abowd, John, et al. "An Uncertainty Principle is a Price of Privacy-Preserving Microdata." Advances in Neural Information Processing Systems 34 (2021).
- Costan, Victor, and Srinivas Devadas. "Intel sgx explained." IACR Cryptol. ePrint Arch. 2016.86 (2016): 1-118.
- Yoon, Jinsung, Daniel Jarrett, and Mihaela Van der Schaar. "Time-series generative adversarial networks." (2019).
- Karwa, Vishesh, and Salil Vadhan. "Finite sample differentially private confidence intervals." arXiv preprint arXiv:1711.03908 (2017).
- Balle, Borja, et al. "Hypothesis testing interpretations and renyi differential privacy." International Conference on Artificial Intelligence and Statistics. PMLR, 2020.
- Mironov, Ilya, Kunal Talwar, and Li Zhang. "R\'enyi Differential Privacy of the Sampled Gaussian Mechanism." arXiv preprint arXiv:1908.10530 (2019).
書籍
- HashHub Researchレポート:
317本(前年比+6本) - 漫画や雑誌等を含めた書籍:
63冊(前年比-117冊)
技術書
昨年より1冊増えたが、腰を据えて読めていない感覚がある。
- みんなのデータ構造, ラムダノート, Pat Morin (著), 堀江 慧 (翻訳), 陣内 佑 (翻訳), 田中 康隆 (翻訳)
- [試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識, 技術評論社, 武内 覚 (著)
- Pythonチュートリアル 第4版, オライリージャパン, Guido van Rossum (著), 鴨澤 眞夫 (翻訳)
- データ解析におけるプライバシー保護 (機械学習プロフェッショナルシリーズ), 講談社, 佐久間 淳 (著)
ビジネス書・趣味
今年の課題感として本を読む時間を生活に組み込めなかったことがある。朝読書復活させる。
記事
昨年に引き続き、あまり記事は読んでいない。
以下では、Pocketでお気に入りしたものからリスト化する。いずれも2021年12月31日時点で有効なリンクのみを対象とした。 概ね読んだ順であり、「2021年に読んでよかった記事」のため2020年以前に公開されたものを含む。体感、去年よりお気に入りにする頻度が下がった。
- 公開APIのインターフェースで利用している外部クレートはRe-exportする(と良さそう) - Qiita
- 2021年のウェブ標準とブラウザ:新春特別企画|gihyo.jp … 技術評論社
- https://keens.github.io/blog/2021/01/04/future_of_proguramming_languages/ プログラミング言語の未来はどうなるか | κeenのHappy Hacκing Blog
- An unsafe tour of Rust’s Send and Sync | nyanpasu64’s blog
- Rust SGX SDK in 4 years - Google スライド
- 今どきの Go の書き方まとめ (2020 年末版) - エムスリーテックブログ
- 重大事故の時にどうするか?|miyasaka|note
- 電子辞書は組み込みLinuxの夢を見るか? - Zopfcode
- Linux Networking Tools: 101 - Speaker Deck
- Rust: A unique perspective
- IIASの列レベルセキュリティ機能で実現する、個人情報マスクの仕組み - ZOZO TECH BLOG
- 解像度を高める 🔬 - Speaker Deck
- 犯罪対策 (AML・CFT) VS プライバシー
- 新しい環境でバリューが出せずに悩んでいる場合の解決法|樫田光 | Hikaru Kashida|note
- プライバシー保護データマイニング(PPDM)手法の種類、特徴を理解する:匿名化技術とPPDM(2)(1/3 ページ) - @IT
- 言語学と音楽学のつながり【民族音楽学】|水里 ☘️|pixivFANBOX
- 再帰的な構造のデータの同値性判定はどうしたらいいか - 貳佰伍拾陸夜日記
- 「それ、どこに出しても恥ずかしくないTerraformコードになってるか?」 / Terraform AWS Best Practices - Speaker Deck
- エクサウィザーズのPMが考える最強のプロダクトマネジメントプロセス / AIプロダクト事業部 宮田大督|エクサウィザーズ HR note
- [2021年版]AWSセキュリティ対策全部盛り[初級から上級まで] というタイトルでDevelopersIO 2021 Decadeに登壇しました #devio2021 | DevelopersIO
- 政治と規制をハックする - プロダクトの社会実装のために - Speaker Deck
- システムインテグレーターとエンタープライズSaaSの交差点|Shunsuke Sagara|note
- Web のセマンティクスにおける Push と Pull | blog.jxck.io
Github
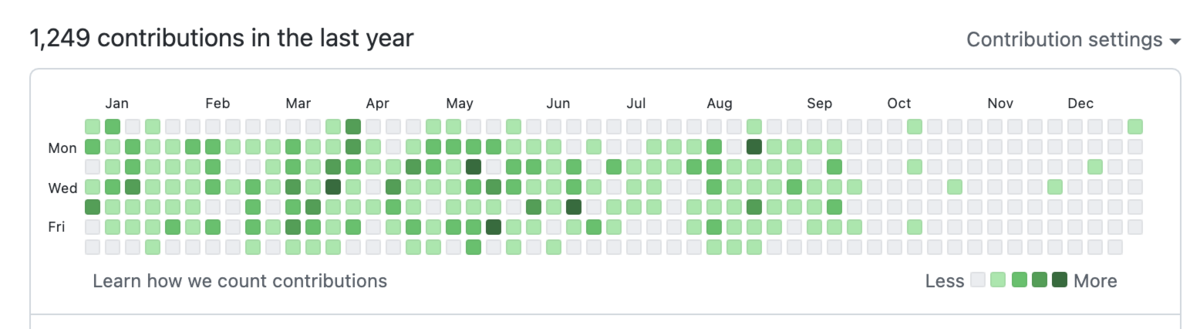
昨年の1,038 contributionsに対して、+211となった。
Scrapbox
765→1376pages